
|
Consideriamo il caso in cui nel seguente grafo delle reti i links "caduti" sono rispettivamente l' 1 e poi il 6, e il protocollo di routing utilizzato sia di tipo link state.
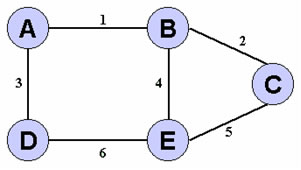
La caduta del link 6 viene rilevata dai nodi D ed E, ma entrambi saranno in grado di distribuire la nuova informazione solo ai loro vicini connessi. Dopo l'esecuzione dell'algoritmo di flooding la rete verrŕ divisa in due parti non connesse, A e D da un lato mentre B, C ed E dall'altro vedranno valori differenti. Questo e' il database visto da A e D:
Da |
A |
Link |
Distanza |
Numero |
A |
B |
1 |
Inf. |
2 |
A |
D |
3 |
1 |
1 |
B |
A |
1 |
Inf. |
2 |
B |
C |
2 |
1 |
1 |
B |
E |
4 |
1 |
1 |
C |
B |
2 |
1 |
1 |
C |
E |
5 |
1 |
1 |
D |
A |
3 |
1 |
1 |
D |
E |
6 |
Inf. |
2 |
E |
B |
4 |
1 |
1 |
E |
C |
5 |
1 |
1 |
E |
D |
6 |
1 |
1 |
mentre questo e' il database visto da B, C ed E:
Da |
A |
Link |
Distanza |
Numero |
A |
B |
1 |
Inf. |
2 |
A |
D |
3 |
1 |
1 |
B |
A |
1 |
Inf. |
2 |
B |
C |
2 |
1 |
1 |
B |
E |
4 |
1 |
1 |
C |
B |
2 |
1 |
1 |
C |
E |
5 |
1 |
1 |
D |
A |
3 |
1 |
1 |
D |
E |
6 |
1 |
1 |
E |
B |
4 |
1 |
1 |
E |
C |
5 |
1 |
1 |
E |
D |
6 |
Inf. |
2 |
Questo non e' molto importante, poiché qualsiasi route da A e D verso B, C o E avverrŕ attraverso un link con una metrica infinita. A e D rileveranno che B, C ed E sono irraggiungibili e altrettanto faranno B, C ed E nei confronti di A e D. Infatti, essi saranno in grado di calcolare questo nuovo stato di routing immediatamente dopo aver ricevuto il nuovo link state senza alcun rischio di impegnarsi in procedure di conteggio all'infinito, tipiche degli algoritmi distance vector. Se le 2 parti rimangono isolate per un lungo periodo, le 2 versioni del database possono evolvere indipendentemente. Ipotizziamo per esempio che il link2 diventi disconnesso. Il database visto da B, C ed E allora diventerebbe:
Da |
A |
Link |
Distanza |
Numero |
A |
B |
1 |
Inf. |
2 |
A |
D |
3 |
1 |
1 |
B |
A |
1 |
Inf. |
2 |
B |
C |
2 |
Inf. |
2 |
B |
E |
4 |
1 |
1 |
C |
B |
2 |
Inf. |
2 |
C |
E |
5 |
1 |
1 |
D |
A |
3 |
1 |
1 |
D |
E |
6 |
1 |
1 |
E |
B |
4 |
1 |
1 |
E |
C |
5 |
1 |
1 |
E |
D |
6 |
Inf. |
2 |
Ma vediamo cosa succede quando uno dei due links viene resettato, riconnettendo di fatto le 2 parti. Distribuire semplicemente l'informazione sul nuovo link potrebbe non essere sufficiente. Supponiamo che sia il link 1 a tornare operativo; i records che lo descrivono verranno corretti in entrambe le parti della rete, ma i records che descrivono i link 2 e 6 saranno ancora incoerenti. Stabilire la connettivitŕ tra 2 nodi richiede qualcosa in piů che semplicemente inviare un record di database. E' necessario garantire che le 2 parti allineino i propri database. Questa procedura e' chiamata "bringing up adjacencies" in OSPF, uno dei principali protocolli di routing basato sulla tecnologia link state. L'allineamento dei due database e' facilitato dall'esistenza degli identificatori di link e dai numeri di versione. Le 2 parti devono sincronizzare i loro database e mantenere solo le versioni piů aggiornate di ciascun record, ad esempio, per ciascun link, il record con il numero piů grande. Tuttavia, implementare un "merge" scambiando copie complete, appare piuttosto inefficiente; nel caso che piů record siano simili nelle 2 copie, non esiste la necessitŕ di inviarli. OSPF risolve questo problema definendo pacchetti di descrizione del database, che contengono solamente gli identificatori dei link ed i corrispondenti numeri di versione. Nella prima fase della procedura di sincronizzazione, entrambi i routers invieranno una completa descrizione dei loro records in una sequenza di pacchetti di descrizione. Dopo la ricezione di questi pacchetti, confronteranno i numeri di sequenza con quelli presenti nel proprio database e prepareranno una lista di "record interessati", ad esempio quando il numero remoto e' maggiore del numero locale o quando l'identificatore di link non e' presente nel database locale . Nella seconda fase, ciascun router richiederŕ al proprio vicino una copia di tali record tramite dei pacchetti cosidetti di "link state request". Come conseguenza della sincronizzazione, molti record verranno aggiornati e verranno inviati ai nodi vicini, utilizzando la normale procedura flooding.
Tutto quanto riportato in questa pagina č a puro scopo informativo personale. Se non ti trovi in accordo con quanto riportato nella pagina, vuoi fare delle precisazioni, vuoi fare delle aggiunte o hai delle proposte e dei consigli da dare, puoi farlo mandando un email. Ogni indicazione č fondamentale per la continua crescita del sito.