
|
Quando lo scheduler manda in esecuzione un processo, quale criterio usa per scegliere tra tutti i processi presenti in coda di ready? Si possono prendere in considerazione diversi obiettivi:
Massimizzare l’utilizzo della CPU( anche se ovviamente questo dipende dal carico);
Massimizzare il Throughput: numero di processi completati in media (nell’unitŕ di tempo);
Minimizzare il Turnaround time: tempo (medio) di completamento di un job, dalla sottomissione all’emissione dei risultati;
Minimizzare il Tempo di attesa: somma del tempo passato dal processo in Ready Queue;
Minimizzare il Tempo di risposta: tempo che intercorre da quando si verifica l’evento che permette ad un processo di eseguire a quando il processo comincia ad eseguire;
Gli algoritmi principalmente utilizzati per realizzare questi obbiettivi sono:
First Come, First Served (scheduling in ordine di arrivo)
Shortest Job First (scheduling per brevitŕ)
Priority scheduling (scheduling per prioritŕ)
Round Robin (scheduling circolare)
Multilevel Queue (scheduling a code multiple)
Multilevel Feedback Queue (sch. a code multiple con retroazione)
First Come First Served (FCFS)
E’ facile da implementare, basta una coda FIFO: il PCB di un processo che entra nella coda dei processi pronti (RQ) e viene messo in fondo alla coda. Quando la CPU si libera viene assegnata al processo il cui PCB č in testa alla coda FIFO. Con FCFS il tempo di attesa del completamento di un processo č spesso lungo ed essendo inoltre FCFS un algoritmo non preemptive, non va bene per i sistemi time-sharing. Supponiamo tre processi che arrivano assieme e che entrano in CPU nell’ordine P1, P2, P3. I tre processi hanno i seguenti tempo di esecuzione di CPU, e poi terminano.

Il diagramma di Gantt per questa sequenza č:

I tempi di attesa: per P1 = 0; P2 = 24; P3 = 27 e di conseguenza il tempo medio di attesa: (0 + 24 + 27)/3 = 17. Supponiamo che l’ordine di arrivo sia: P2 , P3 , P1, il diagramma di Gantt per questa sequenza sarŕ:
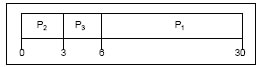
Tempo di attesa per P1 = 6; P2 = 0; P3 = 3 e di conseguenza il tempo medio di attesa: (6 + 0 + 3)/3 = 3, molto meglio del caso precedente. Si puň quindi facilmente intuire l’ inefficienza di questo tipo di algoritmo di scheduling.
Il suo nome esatto č “Shortest Next CPU Burst”. Si esamina la durata del prossimo burst di CPU di ciascun processo e si assegna la CPU a chi ha il burst di durata minima. Puň essere usato in modo pre-emptive oppure non preemptive. Nel caso preemptive, se arriva in coda ready un processo il cui burst time č inferiore a quanto rimane da eseguire al processo attualmente running, quest’ultimo viene interrotto e la Cpu passa al nuovo processo. Questo schema č noto come Shortest-Remaining- Time-First (SRTF). Si puň dimostrare che SJF č ottimale: spostando uno processo breve prima di uno lungo (anche se quest’ultimo č arrivato prima) si migliora l’attesa del processo breve piů di quanto si peggiori l’attesa del lungo ed il tempo medio di attesa diminuisce! C’ è perň un problema. Purtroppo, in generale la durata del prossimo burst di CPU di un processo non č nota, allora possiamo cercare di stimare il prossimo CPU burst sulla base dei precedenti.
Priority scheduling (scheduling per prioritŕ)
Un valore di prioritŕ (di solito un numero intero) č associato ad ogni processo. La CPU č allocata al processo con la prioritŕ migliore. Certi sistemi codificano prioritŕ alta con valori piccoli, altri con valori alti. Noi assumiamo prioritŕ alta con valori piccoli, di solito questo semplifica il calcolo della prioritŕ dei processi, che puň dover essere aggiornato periodicamente. Anche SJF č un tipo di scheduling a prioritŕ: la durata prevista del prossimo burst time č la prioritŕ corrente di ogni processo. In generale, il calcolo della prioritŕ dei processi puň essere:
interna al sistema: calcolata dal sistema operativo sulla base di quantitŕ caratteristiche del comportamento di ogni processo
esterna al sistema: assegnata con criteri esterni al SO
Che succede perň se un processo in attesa della CPU ha sempre una prioritŕ peggiore (cioč misurata da un numero piů alto) di qualche altro processo in RQ? Il processo attende indefinitamente la CPU. Si dice che va in starvation (muore di fame...) Per risolvere questo problema si usa un meccanismo detto aging (invecchiamento): la prioritŕ di un processo in attesa della CPU viene aumentata dal SO man mano che il tempo passa.
Ogni processo ha a disposizione una piccola quantitŕ di tempo di CPU (quanto di tempo), prefissato e uguale per tutti (di solito da 10 a 100 millisecondi). Se entro questo arco di tempo il processo non lascia la CPU, viene interrotto e rimesso in RQ. La RQ č vista come una coda e si verifica quindi un “girotondo” di processi. Il RR č particolarmente adatto per il Time Sharing. Il comportamento del RR dipende molto dal valore del quanto di tempo q scelto: se q tendente a infinito rende RR uguale a FCFS, se q tendente a zero produce un maggior effetto di “parallelismo virtuale” tra i processi perň aumenta il numero di context switch, e quindi l’overhead. L’ efficenza non migliora necessariamente se si aumenta il quanto q, ma puň migliorare se la maggior parte dei processi ha un burst minore di q. D’altra parte, se q č troppo grande diventa un FCFS, e non va bene per il time sharing. Una regola pratica che si puň adottare č che l’80% dei CPU burst dovrebbe essere minore di q.
Tutto quanto riportato in questa pagina č a puro scopo informativo personale. Se non ti trovi in accordo con quanto riportato nella pagina, vuoi fare delle precisazioni, vuoi fare delle aggiunte o hai delle proposte e dei consigli da dare, puoi farlo mandando un email. Ogni indicazione č fondamentale per la continua crescita del sito.