
|
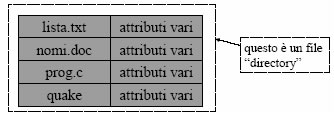
Un File System (FS) puň essere molto grande: decine di migliaia di file, centinaia di gigabyte di disco. Occorre una organizzazione per poter accedere a tutti questi dati in tempi ragionevoli. In particolare, č fondamentale che i tempi di accesso ai singoli file (dati e attributi) NON crescano linearmente con il numero dei file e con lo spazio disco occupato. Si organizzano per tanto i file mediante un sistema di Directory. Una directory “contiene” dei file, nel senso che permette di risalire a tutte le informazioni relative ad un file. Le directory devono essere logicamente organizzate in modo da fornire un minimo di efficienza di recupero delle informazioni contenute. Nella maggior parte dei casi, le directory sono esse stesse dei file, che perň contengono informazioni relative ad altri file. Un file “directory” contiene un certo numero di entry, una per ogni file di quella directory. Ogni entry contiene il nome di un file e una o piů informazioni aggiuntive. Una prima possibilitŕ č di inserire, a fianco del nome di ogni file, i suoi attributi (dimensioni, data d creazione/accesso, tipo...) e informazioni sufficienti per sapere dove č memorizzato il file sull’ hardware; questa č la soluzione adottata dal ms-dos.
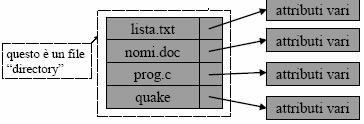
Alternativamente, possiamo inserire, a fianco del nome di ogni file, solo un puntatore ad una struttura interna gestita direttamente dal SO in cui sono contenute tutte le informazioni su quel file: questa č la soluzione adottata da Unix.
Come possiamo organizzare i file di un file system mediante le directory? Nel caso piů semplice, un’unica directory “contiene” tutti i file del FS. E’ la soluzione piů facile da implementare, ma file di utenti diversi non possono avere lo stesso nome, i file non possono essere raggruppati separatamente e la ricerca di un file puň essere molto inefficiente. Un ovvio miglioramento consiste nell’avere una (user file) directory per ogni utente, e poi una (master file) directory che “punta” o “contiene” le directory degli utenti. Emerge il concetto di pathname dei file, ovvero il percorso che si deve compiere a partire dalla master file directory per raggiungere un file. I file di utenti diversi sono raggruppati separatamente per cui anche la ricerca di un file č piů efficiente, ma tutti i file di un utente sono ancora tenuti insieme. Naturale generalizzazione del concetto di directory a due livelli sono le directory a piů livelli. Una directory puň contenere file e altre directory, e cosě via ricorsivamente. Il file system assume cosi l’aspetto di una struttura ad albero.
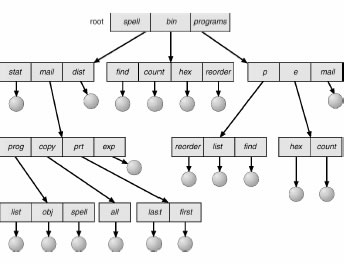
In una User File Directory, l’utente proprietario puň inserire file e altre directory (e cosě via ricorsivamente), in modo da modellare a piacere la porzione di albero che fa capo alla propria User File Directory. La User File Directory č piů comunemente nota come Home Directory. La master File Directory č piů comunemente nota come Root (la radice dell’albero). Durante l’uso del sistema, ogni utente č in ogni momento “posizionato” su una delle sue directory: la current directory (o “working directory”) Il pathname di un file puň essere assoluto (cioč a partire dalla radice) oppure relativo alla current directory. Il pathname assoluto di un file inizia sempre con la radice dell’albero. Nel caso di ms-dos/windows, la radice puň ulteriormente essere preceduta dal nome del volume a cui si fa riferimento (C: A: e cosě via).
/ “slash” = la radice di un FS unix
\ “back slash” = la radice di un volume ms-dos/windows
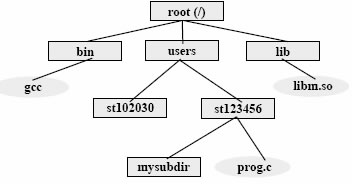
Un pathaname relativo non inizia mai con / o \, ma con il nome di una directory diversa dalla radice. Il pathname (relativo o assoluto) viene normalmente usato come argomento di un comando o di una system call. Ad esempio, in UNIX: fopen (“/users/st13456/prog.c”, “w”). I pathname si usano anche nei sistemi a finestre: un eseguibile che debba lavorare su un file, deve comunque fare riferimento al file usando il suo pathname. La struttura ad albero non permette di condividere file o directory. Questo č un grosso limite alla condivisione e alla cooperazione. Due utenti che lavorano allo stesso progetto possono aver bisogno condividere una sottodirectory. In questo caso la directory dovrebbe risultare una sottodirectory della directory riservata a ciascun utente. Se lo si desidera, lo stesso file (o al limite una intera directory) dovrebbe poter essere visto da directory diverse. Il risultato č quello di una strutturazione a grafo aciclico delle directory. In alcuni sistemi questo risultato viene garantino con l’utilizzo di link simbolici.
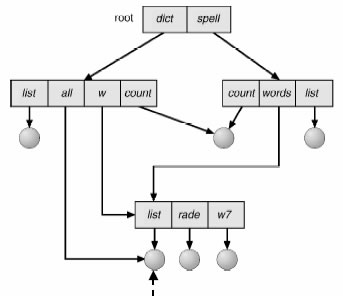
I link (collegamento) sono elementi di directory speciali che contengono il pathname relativo o assoluto della sottodirectory o file da condividere. Uno dei problemi principali della strutturazione a grafo aciclico delle directory č l’implementazione della cancellazione. Nel caso di Unix se viene cancellato un link simbolico l’operazione non influisce sul file originale. Se invece viene cancellato il file, il link viene mantenuto e continua a puntare a quell’area, per poterlo rimuovere servirebbe infatti una lista dei link associati ad ogni file. Sempre in Unix esiste un secondo tipo di link detto hard link. Nel caso di hard link i file possono essere rimossi solo se tutti i loro link sono giŕ stati rimossi. Per implementare questa tecnica occorre registrare nella struttura associata ai file un contatore del numero di riferimenti al file stesso.
Tutto quanto riportato in questa pagina č a puro scopo informativo personale. Se non ti trovi in accordo con quanto riportato nella pagina, vuoi fare delle precisazioni, vuoi fare delle aggiunte o hai delle proposte e dei consigli da dare, puoi farlo mandando un email. Ogni indicazione č fondamentale per la continua crescita del sito.