
|
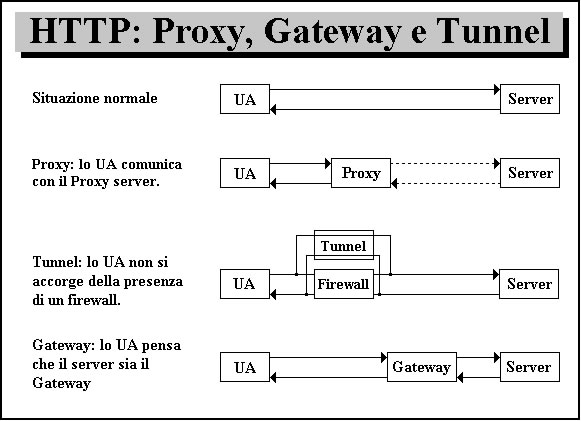
L'HTTP č l'abbreviazione di HyperText Transfer Protocol. E’ il protocollo di trasferimento di ipertesti usato nel World Wide Web per scambiare documenti HTML. L’HTTP, al contrario dei protocolli FTP, Telnet, SMTP ecc., che sono nati per determinate applicazioni (quindi per trasferire dati di un certo tipo), č stato pensato esplicitamente per trasferire dati di qualsiasi tipo. L’ HTTP č un protocollo di trasferimento dati che si appoggia al TCP. Attualmente la versione piů aggiornata č la 1.1, ma sono ancora diffusissime le versioni precedenti, in particolare la 0.9, che č stata largamente usata, e la 1.0. La porta del TCP normalmente usata č la 80. Il protocollo HTTP č il metodo di accesso piů comunemente usato. Esso necessita di un programma sul computer di destinazione che comprenda e risponda a questo protocollo. Quando si digita un URL in un browser (Netscape o Explorer per esempio), il browser manda l'URL al webserver, che esamina la richiesta e risponde. Di solito, la risposta č l'invio di un file HTML ed eventuali file multimediali associati, presi dal filesystem del server. Una delle caratteristiche piů interessanti di questo protocollo č il fatto di essere di tipo request/response: la connessione viene stabilita dal client e chiusa dal server. La richiesta inviata dal client comprende una intestazione e il corpo del messaggio (questo secondo lo standard MIME); il server, ricevuta la richiesta, provvede al recupero del documento e lo spedisce al client in risposta. Viene cosě chiusa la connessione. Invece per l’HTTP 1.1 e una variante particolare dell’HTTP 1.0 dopo la response la connessione non viene terminata e si procede con una nuova coppia request/response. Quindi con l’HTTP 1.1, le connessioni TCP possono essere utilizzate per gestire transazioni request/response multiple. Questa variante č stata introdotta perché prima le pagine HTML erano abbastanza semplici e un collegamento per una richiesta di una pagina era abbastanza breve; mantenere un collegamento aperto per fare una request/response e aspettare un’altra request sarebbe stato piů costoso, in termini di risorse del server, che abbattere e riaprire la connessione, cosě da poter servire qualche altro utente tra una transazione e l'altra. Invece le pagine che si trovano oggi in Internet sono piene di immagini oltre al testo, quindi per visualizzare una pagina si ha bisogno di piů file per ciascuno dei quali č necessaria una transazione request/response. Per questo nelle versioni attuali č meglio non abbattere la connessione. Si puň notare che la request e la response sono di tipo MIME, ossia sono una forma di messaggio di tipo testo. Infatti la base del MIME č il testo, tutto ciň che non č testo (immagini, suoni) viene riportato in forma testuale. Una particolaritŕ dell’HTTP č la possibilitŕ di inserire opportune entitŕ per gestire il cammino dal client al server e viceversa. La chain č il percorso logico che request e response seguono per andare rispettivamente dal client al server e viceversa. Ci sono tre entitŕ di rete che possono modificare la chain: il PROXY, il GATEWAY ed il TUNNEL.
Come abbiamo giŕ detto, dopo aver stabilito una connessione, un client HTTP puň inviare una richiesta. Un client HTTP, tipicamente, richiede al server di trasferire un file (documento ipertestuale, immagine, suoni, animazioni, documenti video). La richiesta di documenti trasmessa dal client su Web specifica il nome del file, un indirizzo Internet ed un metodo d’accesso (tipicamente un protocollo) per reperire il file richiesto. La combinazione di questi elementi si chiama Universal Resource Identifier o URI (URL). Per saperne di piů consulta i seguenti approfondimenti:
Tutto quanto riportato in questa pagina č a puro scopo informativo personale. Se non ti trovi in accordo con quanto riportato nella pagina, vuoi fare delle precisazioni, vuoi fare delle aggiunte o hai delle proposte e dei consigli da dare, puoi farlo mandando un email. Ogni indicazione č fondamentale per la continua crescita del sito.